




































 Математика
МатематикаПохожие презентации:










Анализ социально-экономических процессов
1.
Российский государственныйгидрометеорологический университет
Лекция 7
на тему
«Использование законов распределения
случайных величин при имитации
экономических процессов»
по дисциплине
«Анализ социально-экономических процессов»
Лектор: к.ф.-м.н., доцент, заведующая кафедрой Высшей
математики и физики Зайцева И.В.
2. Вопросы:
1. Равномерное распределение напроизвольном интервале
2. Моделирование дискретных случайных
величин
3. Моделирование непрерывной случайной
величины
Контрольные вопросы.
3. 1. Равномерное распределение на произвольном интервале
Рассмотрим важное и очень простое равномерноераспределение на интервале (m-s, m+s). Плотность
вероятностей этого распределения описывается
следующей формулой.
0, t m s;
1
p ( t ) , m s t m s;
2s
0, t m s,
где m - математическое ожидание;
s - максимальное отклонение от математического ожидания.
Такое распределение используется, если об интервалах
времени известно, что они имеют максимальный разброс,
и ничего не известно о распределениях вероятностей этих
интервалов.
4.
Равномерное распределение можно использовать прирасчетах по сетевым графикам работ. Оно может
применяться и при расчетах основных длительностей и
времен в военном деле.
Формула для определения дисперсии получается после
получения второго момента:
2
( m s ) ( m s )
s2
D T
12
3
5. 2. Моделирование дискретных случайных величин
Дискретная случайная величина Y принимает значения y1<=y2<=… <= yj<=… с вероятностями p1, p2, …, pj,…
составляющими дифференциальное распределение
вероятностей
Y
y1
y2
…
yj
P
p1
p2
…
pj
При этом интегральная функция распределения
m
F p j ; ym y ym 1 ; m 1,2,...;
j 1
F 0; y y1
…
…
6.
Для получения дискретных случайных величин можновоспользоваться методом обратных функций: если X –
равномерно распределенная на интервале (0,1) случайная
величина, то искомую случайную величину получают
при выполнении следующих действий:
Если x1< p1 , то Y= y1 , иначе,
Если x1< p1 + p2, то Y= y2 , иначе,
m
p
j
Если x1< j 1 , то Y= ym , иначе,
Дискретное распределение (общий случай). Предположим,
что известны частоты i выбора из N объектов на
определенном интервале времени, i=1,..., N. Пример
таких частот для N=7 представлен в табл. 1. Первая
строка таблицы - это номер объекта, а вторая - частота его
выбора. Требуется разработать программную функцию,
которая должна возвращать значение номера объекта в
соответствии
7.
Таблица 1Значения обратных функций для получения дискретного
распределения
i
1
2
3
4
5
6
7
xi
130
5
11
44
32
2
67
i
0,447
0,017
0,038
0,151
0,110
0,007
0,230
i
0,447
0,464
0,502
0,653
0,763
0,770
1,000
8.
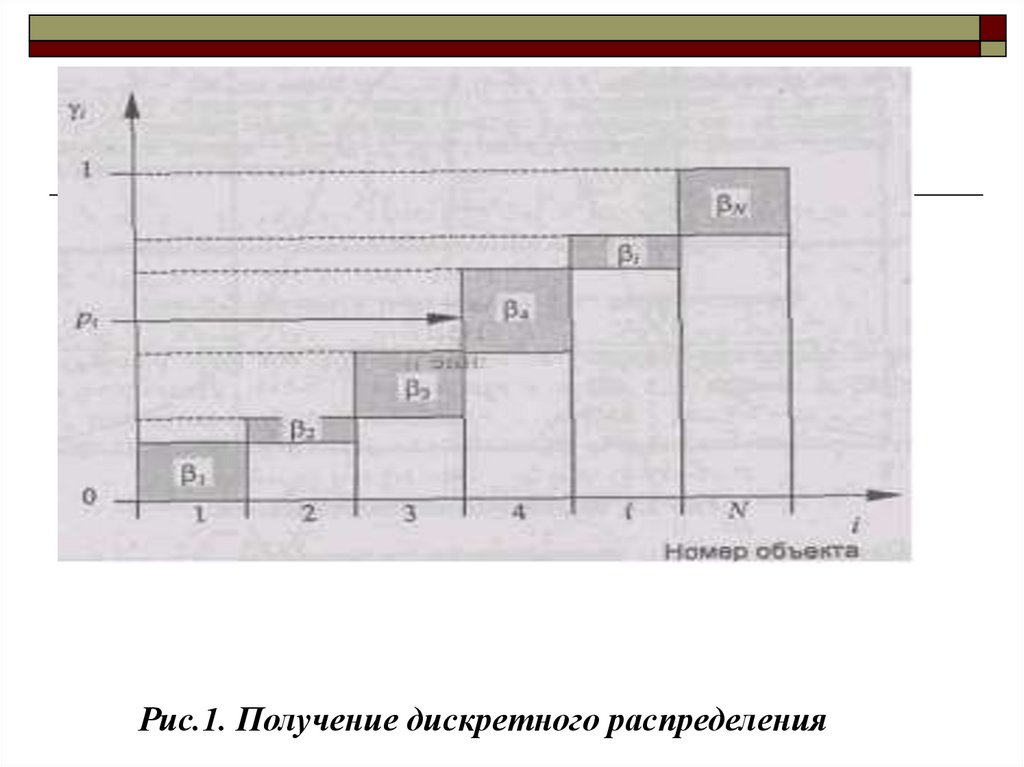
Воспользуемся методом обратных функций. Сначала найдемсумму всех частот N , получим S=291. После
i
i 1
этого построим таблицу нормированных значений
i=xi/ (третья строка табл. 1). Далее рассчитаем r
значения дискретной функции по формуле: .
r
i
i 1
Полученные значения находятся в четвертой строке табл. 1.
Построим график дискретной функции (рис. 1.). Выбор
объекта с номером i осуществляется при выполнении
соотношения i-1 < pt <= i
9.
Рис.1. Получение дискретного распределения10. 3. Моделирование непрерывной случайной величины
Для получения непрерывных случайных величин с заданнымзаконом распределения, как и для дискретных величин,
можно воспользоваться методом обратной функции. Если
случайная величина Y имеет плотность распределения
f(y), то распределение случайной величины
y
F ( y ) f ( y )dy
является равномерным на0 интервале (0,1). Чтобы получить
число, принадлежащее последовательности случайных
чисел {yi}, имеющих функцию плотности f(y),
необходимо разрешить относительно yi уравнение
11.
yx i f ( y )dy
0
где xi - число, принадлежащее последовательности
случайных чисел равномерно распределенных на
интервале от (0,1).
Пример. Необходимо получить случайные числа с
показательным законом распределения (например,
интервалов времени между поступлениями заявок на
обслуживание):
t
t
x i e t dt
f ( t ) e
x i 1 e t
0
ln( 1 x i ) ln e t
t
1
ln( 1 x i )
12.
1 xi- случайное число, имеющее равномерноераспределение на интервале (0,1). Тогда
t
1
Этот способ получения случайных
чисел с заданным законом распределения имеет
ограниченную сферу применения, так как для многих
законов распределения, встречающихся в практических
задачах моделирования, интеграл не берется, т.е.
приходится прибегать к численным методам решения,
что увеличивает затраты вычислительных ресурсов на
получение каждого числа; даже для случаев, когда
интеграл берется в конечном виде получаются формулы,
содержащие действия логарифмирования, извлечения
корня и т.д., что также резко увеличивает затраты
машинного времени на получение каждого случайного
числа.
ln x i
13.
Поэтому на практике часто пользуются приближеннымиспособами преобразования случайных чисел, которые
можно классифицировать следующим образом:
универсальные способы, с помощью которых можно
получать случайные числа с законом распределения
любого вида;
неуниверсальные способы, пригодные для получения
случайных чисел с конкретным законом распределения.
Рассмотрим приближенный универсальный способ
получения случайных чисел, основанный на кусочной
аппроксимации функции плотности.
14.
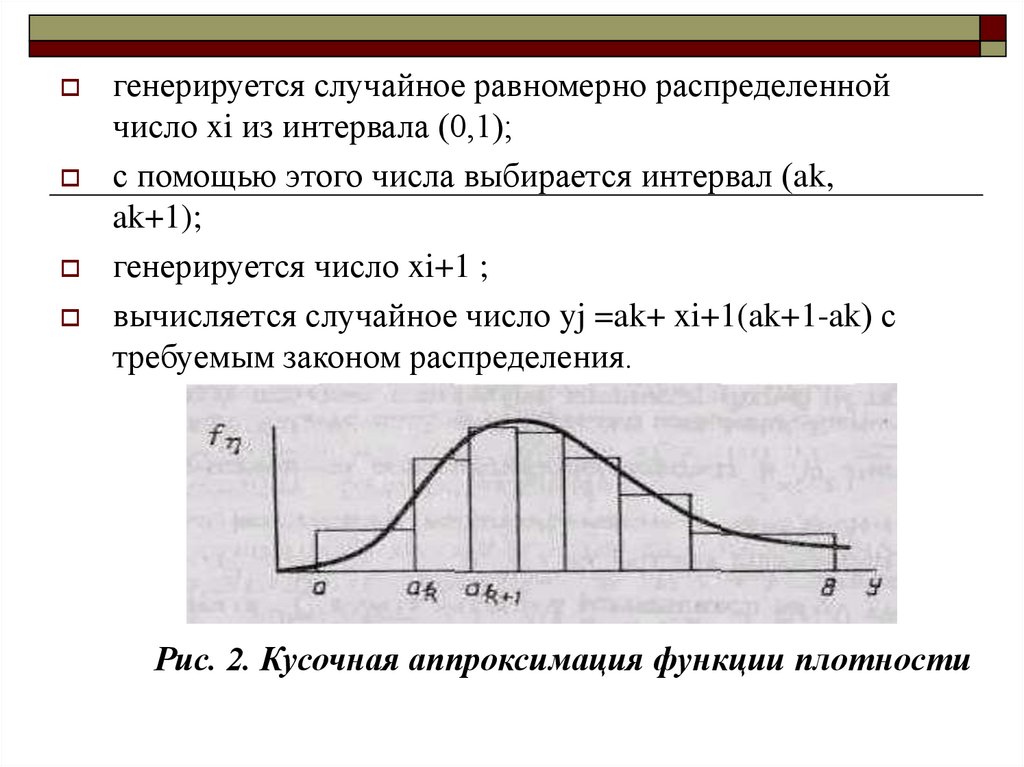
Пусть требуется получить последовательность случайныхчисел {yj} с функцией плотности f (y) , значения которой
лежат в интервале (a,b). Разобьем интервал (a,b) на m
интервалов (рис.2), и будем считать f (y) на каждом
интервале постоянной. Разбивать необходимо так, чтобы
вероятность попадания случайной величины в любой
интервал (ak, ak+1) была постоянной, т.е.:
ak 1
f ( y )dy 1 / m
ak
В таком случае, алгоритм этого способа получения
случайных чисел сводится к выполнению следующих
действий:
15.
генерируется случайное равномерно распределеннойчисло xi из интервала (0,1);
с помощью этого числа выбирается интервал (ak,
ak+1);
генерируется число xi+1 ;
вычисляется случайное число yj =ak+ xi+1(ak+1-ak) с
требуемым законом распределения.
Рис. 2. Кусочная аппроксимация функции плотности
16.
Нормальное распределение. Нормальное, или гауссовораспределение, - это, несомненно, одно из наиболее
важных и часто используемых видов непрерывных
распределений. Оно симметрично относительно
математического ожидания. Сначала остановимся на
фактическом смысле этого распределения применительно
к экономическим задачам и сформулируем центральную
предельную теорему теории вероятностей в следующей
практической интерпретации.
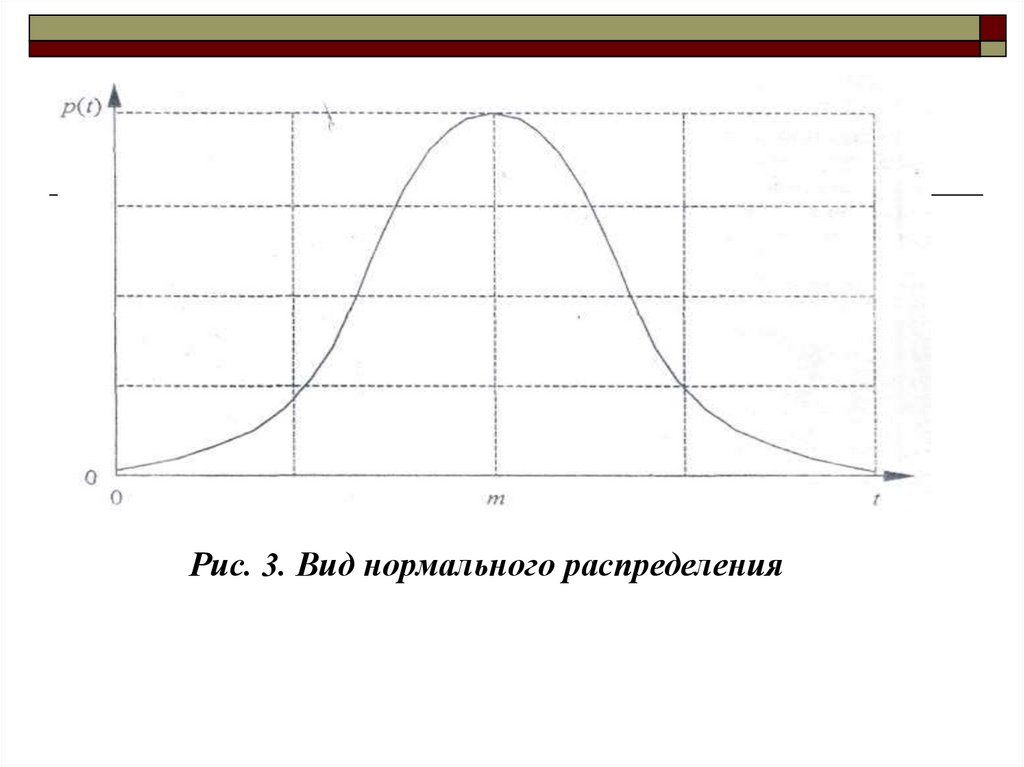
Непрерывная случайная величина t имеет нормальное
распределение вероятностей с параметрами m и > 0,
если ее плотность вероятностей имеет вид (рис. 3):
где m – математическое ожиданиеM[t];
- среднеквадратичное отклонение.
17.
Рис. 3. Вид нормального распределения18.
Причем если D[t] - это дисперсия, то . D[t ]Рассмотрим временные диаграммы на рис. 4. Предположим,
что какой-то случайный процесс состоит из
последовательности n элементарных независимых
процессов. Длительность каждого элементарного
процесса ti - это случайная величина, распределенная по
неизвестному закону с математическим ожиданием и
дисперсией . Допустим, что это непрерывное
распределение (допущение, справедливое для
нормальной жизни общества, где существует природная
инертность), причем третий момент должен иметь
ограничение по абсолютной величине (это также,
естественно, реальное условие). Справедливо
соотношение
19.
Рис. 4. Интерпретация нормального распределенияТеорема 1 (без доказательства). Если сделать предельный
переход и устремить n , то распределение случайной
величины t=T{n} устремится к нормальному с
математическим ожиданием M[t] и дисперсией D[t],
определяемыми из следующих соотношений:
20.
Практический смысл этой теоремы очень прост. Любыесложные работы на объектах экономики (ввод информации из
документа в компьютер, проведение переговоров, ремонт
оборудования и др.) состоят из многих коротких
последовательных элементарных составляющих работ. Причем
количество этих составляющих работ иногда настолько велико,
что требования в приведенной выше теореме о независимости и
одинаковом распределении становятся излишними. Поэтому
при оценках трудозатрат всегда справедливо предположение о
том, что их продолжительность - это случайная величина,
которая распределена по нормальному закону.
21.
Рассмотрим пример применения способа преобразованияпоследовательности равномерно распределенных
случайных чисел {xi} в последовательность с заданным
законом распределения {yi} на основе предельных теорем
теории вероятностей. Такие способы ориентированы на
получение последовательностей чисел с конкретным
законом распределения, т.е. не являются универсальными.
Пример. Пусть требуется получить последовательность
случайных чисел {yi}, имеющих нормальное
распределение с математическим ожиданием m и средним
квадратическим отклонением :
2
p( t )
1
2
e
( t m )
2 2
22.
Будем формировать случайные числа tj в виде суммпоследовательностей случайных чисел {xi}, равномерно
распределенных на интервале от (0,1). Можно
воспользоваться центральной предельной теоремой: Если
X1 , X2,..., Xn - независимые одинаково распределенные
случайные величины, имеющие математическое
ожидание M(Xi)=a и дисперсию 2, то при N сумма
N
асимптотически нормальна с математическим
X i ожиданием Na и средним квадратическим
i 1
отклонением
N
Практически достаточно N=8 12, а в простейших случаях 4 5. Преимущество этого способа - высокое быстродействие.
Недостатком является игнорирование «хвостов» нормального
распределения, которые могут уходить в обе стороны от
величины m на расстояние, превышающее 6 .
23.
Поэтому при проведении особо точных экспериментовприменяются другие - более точные (но более
медленные) способы. В современных системах
имитационного моделирования обычно используются не
менее двух программных датчиков случайных величин,
распределенных по нормальному закону (их выбор
осуществляется автоматически управляющей
программой).
Экспоненциальное распределение. Оно также занимает очень
важное место при проведении системного анализа
экономической деятельности. Этому закону
распределения подчиняются многие явления, например:
время поступления заказа на предприятие;
посещение покупателями магазина-супермаркета;
24.
телефонные разговоры;срок службы деталей и узлов в компьютере,
установленном,
например, в бухгалтерии.
Рассмотрим это распределение подробнее. Если
вероятность наступления события на малом интервале
времени t очень мала и не зависит от наступления других
событий, то интервалы времени между последовательностями
событий распределяются по экспоненциальному закону с
плотностью вероятностей
25.
Особенностью этого распределения являются его параметры:математическое ожидание
;
дисперсия
Математическое ожидание равно среднеквадратичному
отклонению, что является одним из основных свойств
экспоненциального распределения.
На первый взгляд, это распределение является надуманным.
Поэтому рассмотрим предельную теорему о
суперпозиции потоков. Предположим, что можно
наблюдать к независимых потоков событий (рис. 5). В
каждом таком потоке можно наблюдать mj элементарных
событий, j = 1, ... , к. Интервалы времени между
событиями - это независимые случайные величины,
распределенные по неизвестному закону с
математическим ожиданием 1/ j
26.
Спроектируем моменты всех событий на общую ось времении рассмотрим случайный интервал времени t=T{k}
между двумя событиями полученного суммарного
потока, состоящего из n событий, где
Теорема 2 (без доказательства). Если сделать предельный
переход и устремить n , то распределение случайной
величины интервала t=T{k} в суммарном потоке
событии, состоящем из к элементарных потоков,
устремится к экспоненциальному с математическим
ожиданием
Следствие (без доказательства). Поток заявок, интервал
поступления которых в некую систему имеет
экспоненциальное распределение, является простейшим.
27.
Рис. 5. Интерпретация предельной теоремы осуперпозиции потоков событий
28.
Прокомментируем практический смысл этой теоремы.Допустим, что имеется некая крупная фирма. Клиенты
фирмы - это физические и юридические лица. Каждый из
них может иметь набор планов и расписанных дел на
значительном интервале времени. Однако если
рассмотреть суммарный поток обращений этих клиентов
к служащим фирмы по разным вопросам, то интервал
времени между двумя последовательными обращениями
в соответствии с рассмотренной теоремой являемся
случайной величиной, распределенной по
экспоненциальному закону.
Обобщенное распределение Эрланга. Обычно распределение
Эрланга используется в случаях, когда длительность
какого-либо процесса можно представить как сумму к
элементарных последовательных составляющих,
распределенных по экспоненциальному закону. Если
обозначить математическое ожидание длительности
всего процесса как M[t]=1/ , среднюю длительность
элементарной составляющей как 1/ , то плотность
вероятностей распределения Эрланга представляется
следующей формулой:
29.
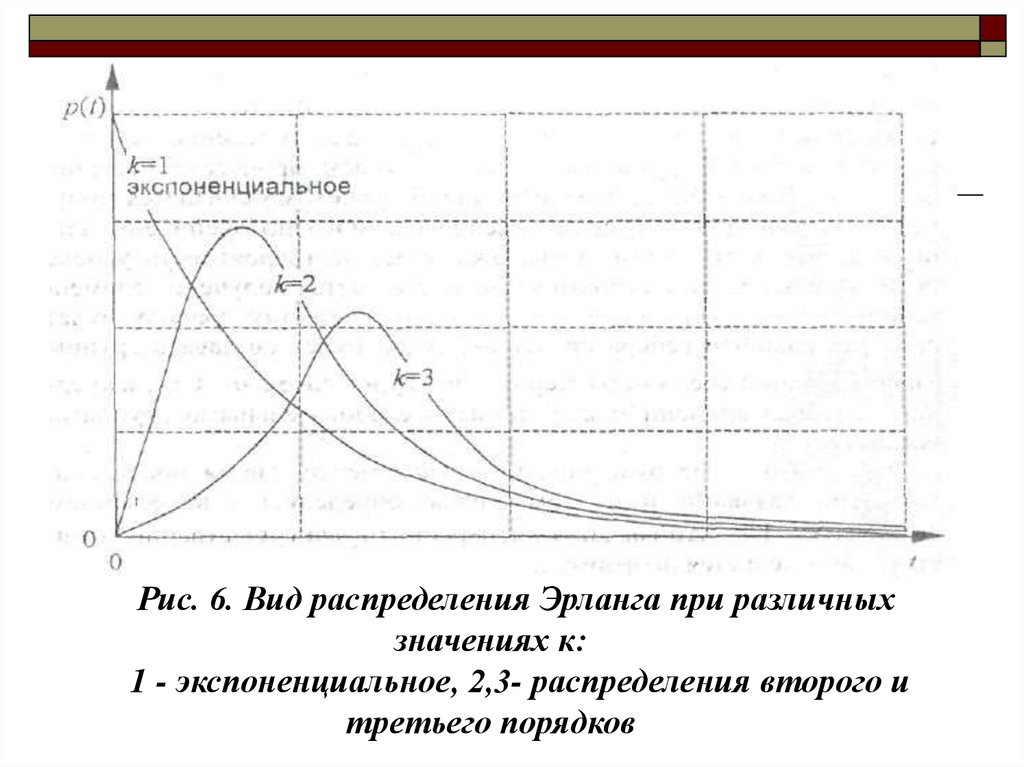
12 k
При к = 1 – это экспоненциальное распределение.
Разновидности этого распределения для разных к > 0
представлены на рис. 6.
Предположим, что. в распределении Эрланга имеется не
строго фиксированное число экспоненциально
распределенных отрезков к, а переменное, с вероятными
изменениями в пределах одного интервала. Тогда можно
говорить лишь о средней величине s таких отрезков, где s число с плавающей точкой. После такого перехода от
дискретных к непрерывным величинам появляется
возможность работы и со значениями в пределах 0 <s <1.
Дисперсия такого распределения D[t ]
30.
Видно, что при значениях s > 1 (в том числе целых) получаемобычное распределение Эрланга с параметрами: M[t] =
ms = 1/ и D[t] = m2s = 1/ 2к. Однако при 0 < s < 0 это
распределение меняется коренным образом: фактически
мы получаем процесс испытаний Бернулли В результате
этих испытаний «успехом» считается получение
элементарного отрезка, распределенного по
экспоненциальному закону с математическим ожиданием
m (вероятность успеха равна s), а неудачей с
вероятностью 1 - s является получение элементарного
отрезка с нулевой длиной. Если по такому правилу будет
работать какой-то генератор заявок, то он будет создавать
группы заявок. Причем средний размер группы будет
равен , а средний интервал времени между двумя
последовательными группами равен m.
31.
Рис. 6. Вид распределения Эрланга при различныхзначениях к:
1 - экспоненциальное, 2,3- распределения второго и
третьего порядков
32.
Математическое ожидание интервала между двумяпоследовательными заявками и в этом случае
определяется выражением M[t] = ms = 1/ . Что касается
дисперсии, то она существенно меняется и определяется
по формуле:
Одно из свойств групповых потоков заключается в том, что
среднеквадратичное отклонение интервала между
заявками превосходит математическое ожидание этого
интервала.
Если имеется возможность собрать статистику по
групповому потоку на практике или получить такой
лоток с помощью рассмотренной выше программной
функции, то можно определить коэффициент вариации с
и связь этого коэффициента со средним размером
группы заявок по формуле
33.
Это соотношение позволяет отслеживать появлениегрупповых потоков в реальных системах или в их
имитационных моделях.
Обобщенное распределение Эрланга применяется при
создании как чисто математических, так и имитационных
моделей в двух случаях.
Во-первых, его удобно применять вместо нормального
распределения, если модель можно свести к чисто
математической задаче, применяя аппарат марковских
или полумарковских процессов либо используя метод
Кендалла. Однако такие модели далеко не всегда
адекватны реальным процессам.
Во-вторых, в реальной жизни существует объективная
вероятность возникновения групп заявок в качестве
реакции на какие-то действия, поэтому возникают
групповые потоки.
34.
Появление групповых потоков в сложных экономическихсистемах приводит к резкому увеличению средних
длительностей различиях задержек (заказов в очередях,
задержек платежей и др.), а также к увеличению
вероятностей рисковых событий или страховых случаев.
Треугольное распределение. Треугольное распределение
применяется в тех случаях, когда о случайной величине
ничего неизвестно, кроме наиболее вероятного значения
и диапазона возможных значений этой случайной
величины (рис. 7).
Рис. 7. Общий случай
треугольного распределения
вероятностей
0
А
С
В
x
35.
Применимость такого распределения рассмотрим напримере, связанном с динамическими характеристиками
системы управления базами данных (СУБД) в
информационной системе.
Пример. Предположим, что база данных находится на
компьютере, не входящем в состав какой-либо
вычислительной сети. Поэтому пользователь,
работающий с этой базой, имеет во время работы
монопольный доступ к ней. Известны структуры и
частоты запросов пользователей к этой базе данных.
Рассмотрим три случая физической организации базы
данных (рис. 8).
Первый случай. Допустим, что администратор базы данных
(системный программист) осуществил физическую
организацию данных, которая обладает следующими
свойствами:
36.
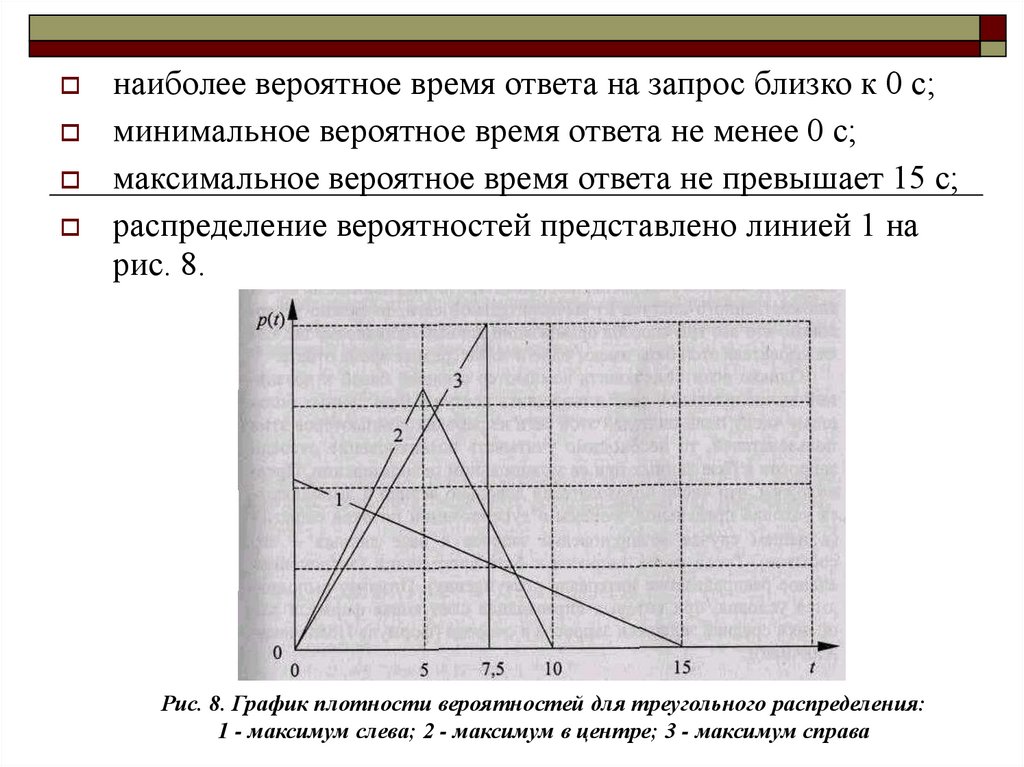
наиболее вероятное время ответа на запрос близко к 0 с;минимальное вероятное время ответа не менее 0 с;
максимальное вероятное время ответа не превышает 15 с;
распределение вероятностей представлено линией 1 на
рис. 8.
Рис. 8. График плотности вероятностей для треугольного распределения:
1 - максимум слева; 2 - максимум в центре; 3 - максимум справа
37.
Этот системный программист обеспечил минимальное времядля наиболее вероятных запросов за счет увеличения
времени для менее вероятных. Среднее время получения
ответа в этом случае t = 5 с.
Второй случай. Администратор базы данных по просьбе
пользователей решил уменьшить время ответа на те
запросы, которые редко возникают. Для этого он
переделал физическую организацию данных и получил
следующие ее свойства:
наиболее вероятное время ответа на запрос равно 5 с;
минимальное вероятное время ответа не менее 0 с;
максимальное вероятное время ответа не превышает 10 с;
распределение вероятностей показано линией 2 на рис. 8.
Таким образом, системный программист обеспечил снижение
времени ответа для менее вероятных запросов за счет
увеличения времени ответа для наиболее вероятных.
Среднее время получения ответа осталось тем же: t = 5 с.
38.
Третий случай. Администратор базы данных решил ещеболее уменьшить время ответа на менее вероятные
запросы. Для этого он опять переделал физическую
организацию данных и получил следующие свойства:
наиболее вероятное время ответа на запрос равно 7,5 с;
минимальное вероятное время ответа не менее 0 с;
максимальное вероятное время ответа не превышает 7,5;
распределение вероятностей изображено линией 3 на рис.
4.
Этот системный программист обеспечил дальнейшее
снижение времени ответа для менее вероятных запросов
за счет увеличения времени ответа для более вероятных.
Среднее время получения ответа и в этом случае не
изменилось: t=5 с.
39.
Если подключить компьютер с нашей базой к локальнойвычислительной сети и разрешить доступ к базе данных
большому числу пользователей этой сети из рабочих
компьютеров этих пользователей, то необходимо
учитывать возникновение очереди запросов к базе
данных при ее монопольном использовании.
Предположим, что число пользователей довольно велико и
выполняются условия предельной теоремы о
суперпозиции потоков событий (в нашем случае
возникновение запроса к базе данных - это событие).
Тогда поток запросов к базе простейший
(экспоненциальное распределение интервала
поступления). Поэтому выполняются условия, при
которых справедлива следующая формула для оценки
средней задержки запросов в очереди (формула
Поллачека-Хинчина):
40.
t s ( 1 c S2 )tq
2( 1 )
где tq - искомая средняя задержка в очереди;
ts - среднее время обслуживания;
- загрузка обслуживающего узла;
сs - коэффициент вариации времени обслуживания.
Если известно среднеквадратичное отклонение времени
обслуживания s, то сs= s/ts . В трех рассмотренных
случаях ts=5 с.
Загрузка не изменяется, так как поток запросов к базе данных
тот же самый. Однако разброс значений в первом случае
примерно в 3 раза больше, чем в третьем. Соответственно
может быть больше приблизительно в 9 раз (т.е. на
порядок!), а это часть множителя в числителе формулы.
41.
После этого можно сделать вывод, что задержка в очереди впервом случае будет значительно больше, чем в третьем.
Во втором случае задержка в очереди также будет
превосходить задержку, возникающую в третьем случае.
Поэтому наиболее рациональным относительно
возникающих задержек является третий способ
организации базы данных. Для получения
последовательностей случайных чисел, подчиненных
треугольному распределению используется метод
обратных функций.
42. Контрольные вопросы:
Какими свойствами обладает распределение,равномерное на интервале?
Что такое нормальное распределение (дать
экономическую трактовку)?
Как получается на практике экспоненциальное
распределение (дать интерпретацию применительно к
экономическим процессам)?
Для чего используется обобщенное распределение
Эрланга?
Какие случайные процессы удобно описывать с
помощью треугольного распределения?
Формула Поллачека-Хинчина?